
En ce moment, tout le monde veut tester l’IA, lancer son premier assistant local, jouer avec les agents, automatiser deux ou trois tâches, ou simplement comprendre ce qu’il se passe derrière la hype.
Mais le problème arrive souvent juste après. On commence avec un abonnement raisonnable, puis on veut aller plus loin. Plus de tests, plus d’automatisation, plus d’appels API, plus de volume. Et là, on découvre la fameuse facturation au token. Sur le papier, ce n’est pas grand-chose. En pratique, ça peut grimper vite si on expérimente beaucoup.
C’est souvent à ce moment qu’on se pose la vraie question :
Et si je faisais tourner un LLM en local ?
On entend souvent que cela consomme trop de ressources, qu’il faut une machine de guerre, ou que cela ne sert à rien face au cloud. Ce n’est pas totalement faux… mais ce n’est pas totalement vrai non plus.
Aujourd’hui, avec les bons modèles quantifiés et les bons outils, on peut déjà faire beaucoup de choses sur une machine perso, un laptop correct, ou même un petit VPS pour certains usages.
Le vrai sujet n’est donc pas seulement peut-on le faire ?
Le vrai sujet est :
Quel modèle choisir selon MA machine et l’usage que je veux en faire ?
Et c’est exactement là que deux outils sortent du lot.
Objectif
Éviter de télécharger un modèle trop lourd ou inutilisable sur votre machine.
Méthode
Comparer rapidement votre RAM, votre GPU et votre usage avec les bons outils.
Résultat
Choisir un modèle local stable, rapide et vraiment adapté à votre contexte.
1. Can I Run AI ?
Un outil web simple, rapide et efficace. Le site analyse les capacités de votre machine directement depuis le navigateur, puis vous aide à identifier quels modèles peuvent tourner correctement chez vous.
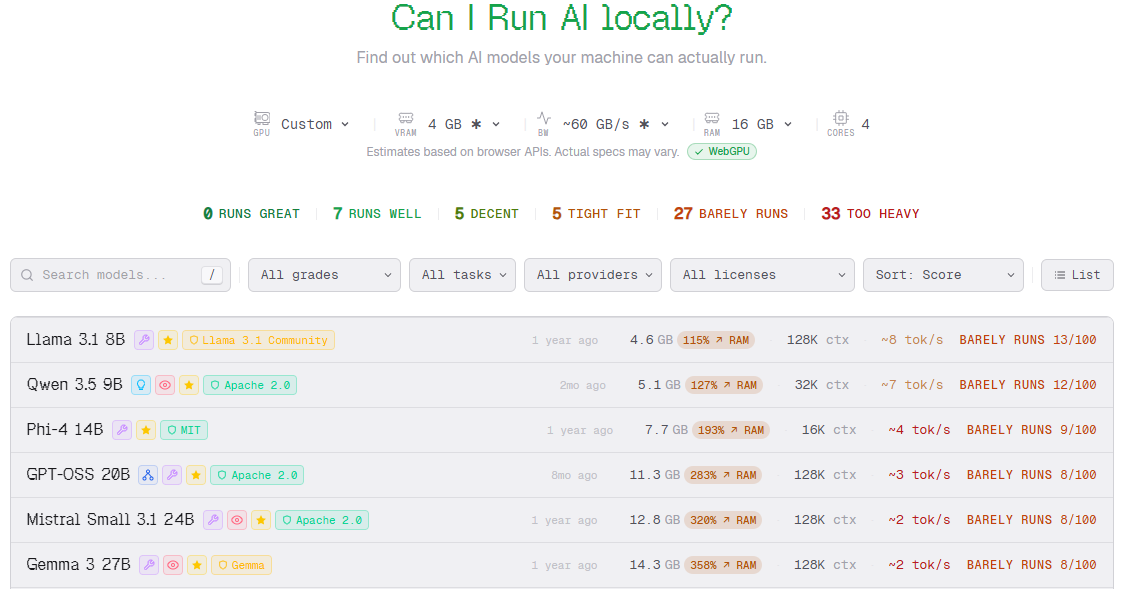
Can I Run AI donne une première lecture rapide du matériel disponible, sans aucune installation, avec une détection instantanée directement depuis le navigateur web.
En quelques secondes, l’outil identifie la configuration de votre machine et propose des modèles cohérents avec les ressources détectées.
- 🖥️ Une Interface claire
- ⚡Aucune installation nécessaire, Détection rapide du matériel, Idéal pour débuter
- 🚀 Vous débutez avec les LLM locaux, vous avez un PC fixe ou portable et vous voulez une réponse rapide
- 🧠 vous ne connaissez pas encore les tailles de modèles (7B, 14B, 32B, etc.)
- 🤔 Permet d’éviter de télécharger un modèle impossible à faire tourner
C’est vraiment le genre d’outil qui évite de perdre deux heures à télécharger et tester des modèles au hasard. Ce serait dommage que des modèles très performants donnent une mauvaise impression simplement parce qu’ils sont lancés sur une machine inadaptée.
Un bon modèle 3B bien adapté à votre configuration sera souvent bien plus agréable à utiliser qu’un 14B complètement étouffé.
2. LLMFit
Autre approche, plus orientée terminal. LLMFit permet d’estimer quels modèles sont adaptés à votre environnement via ligne de commande. Et ça, pour moi, c’est une vraie bonne idée, car bien souvent on fait ces tests sur un environnement Linux en SSH.

LLMFit est pratique quand on teste un serveur ou un VPS directement en SSH.
Pourquoi ? Parce qu’on n’a pas toujours la possibilité, ni l’envie, d’utiliser une interface web.
Sur un serveur ou un VPS, il n’y a pas toujours d’interface graphique disponible. Dans ce contexte, un outil qui s’installe et s’utilise directement depuis le terminal est souvent bien plus logique… et parfois plus précis.
LLMFit va droit au but :
- 🎯Léger, Rapide, efficasse
- 🔐 Utilisable en SSH, parfait pour les admins sys
- 🦙Très bon complément à Ollama ou autres stacks locales
Si, comme moi, vous passez une grande partie de votre temps en SSH, cet outil est clairement dans son élément.
Un vrai petit Htop pour LLM.
Ce qu’il faut comprendre avant de choisir un modèle
Même si ce type d’outils peut aussi aider dans des contextes plus sérieux, comme un déploiement professionnel avec agents IA, LLM dédiés et usages en entreprise, ce n’est pas le sujet ici.
Dans cet article, on parle surtout d’un autre public :
- 🔵 les curieux qui veulent apprendre
- 🔵 les passionnés qui aiment tester
- 🔵 ceux qui recyclent une vieille machine
- 🔵 ceux qui ont un petit VPS sous-utilisé
- 🔵 ceux qui veulent monter un LAB perso
- 🔵 ceux qui rêvent d’un petit agent local utile au quotidien
L’idée n’est donc pas de bâtir une plateforme IA pour 200 utilisateurs, mais de faire quelque chose d’intelligent avec des ressources déjà disponibles.
Avant de choisir un modèle, il faut regarder plusieurs critères.
Le cas d’usage
Un modèle peut être excellent pour une tâche et mauvais pour une autre.
Exemples :
Chat
WhatsApp, Slack
Réponses courtes, assistance rapide et échanges du quotidien.
Code
Scripts, snippets
Aide à écrire, corriger ou expliquer du code simple.
RAG
Docs, bases internes
Répondre à partir de contenus précis déjà indexés.
Agent
Tâches, outils
Enchaîner plusieurs actions avec un minimum de supervision.
Documents
PDF, rapports
Résumer, comparer ou extraire les points importants.
API locale
Ollama, services
Brancher le modèle à vos outils et automatisations.
Automatisation
Jobs, workflows
Gagner du temps sur les tâches répétitives du lab.
Comprendre les tailles de modèles
Quand on parle de 7B, 8B, 14B ou 32B, le B signifie billion en anglais, soit milliard de paramètres.
Les paramètres sont, pour simplifier, les “réglages internes” du modèle. Plus il y en a, plus le modèle peut être capable de gérer des tâches complexes, nuancer ses réponses ou mieux raisonner… mais plus il demandera de ressources.
Il ne faut cependant pas résumer la qualité à ce chiffre seul. L’architecture du modèle, son entraînement, la quantification et l’optimisation jouent aussi un rôle énorme.
7B
Accessible, idéal pour apprendre et lancer un premier lab local.
8B
Excellent équilibre entre qualité, vitesse et consommation mémoire.
14B
Plus confortable pour les tâches complexes, mais plus exigeant.
32B+
À réserver aux machines solides ou aux usages très ciblés.
En clair : plus le chiffre monte, plus les besoins montent aussi.
Les critères techniques
Select Tab
La RAM disponible
C’est souvent le premier facteur limitant. Un modèle trop gros peut saturer la mémoire rapidement, ralentir la machine ou simplement ne jamais démarrer.
Le GPU ou non
La présence d’un GPU peut totalement changer l’expérience. Sans GPU, certains modèles restent utilisables, mais il faudra être plus raisonnable sur leur taille et leurs performances.
Le nombre d’utilisateurs
Un usage personnel n’a rien à voir avec plusieurs utilisateurs connectés en même temps. Un petit serveur peut suffire pour soi, mais s’écrouler en usage partagé.
La vitesse attendue
Si attendre quelques secondes ne vous dérange pas, beaucoup plus d’options deviennent possibles. Si vous cherchez une réponse instantanée, les contraintes ne seront pas les mêmes.
La RAM disponible
C’est souvent le premier facteur limitant. Un modèle trop gros peut saturer la mémoire rapidement, ralentir la machine ou simplement ne jamais démarrer.
Le GPU ou non
La présence d’un GPU peut totalement changer l’expérience. Sans GPU, certains modèles restent utilisables, mais il faudra être plus raisonnable sur leur taille et leurs performances.
Le nombre d’utilisateurs
Un usage personnel n’a rien à voir avec plusieurs utilisateurs connectés en même temps. Un petit serveur peut suffire pour soi, mais s’écrouler en usage partagé.
La vitesse attendue
Si attendre quelques secondes ne vous dérange pas, beaucoup plus d’options deviennent possibles. Si vous cherchez une réponse instantanée, les contraintes ne seront pas les mêmes.
Pour finir
Ne cherchez pas à lancer le plus gros modèle possible.
Cherchez surtout le bon équilibre entre votre besoin réel, les capacités de votre machine et les modèles disponibles
Le LLM local n’est plus réservé aux grosses infrastructures.
- ✅ Oui, il faut rester réaliste sur les ressources.
- ✅ Oui, tout ne tournera pas partout.
- 🤖 Mais non, ce n’est plus inaccessible.
A retenir
Commencez petit, mesurez le confort réel, puis montez en gamme seulement si votre usage le justifie. Avec des outils comme Can I Run AI ou LLMFit, on gagne du temps, on évite les mauvais choix et on peut démarrer plus intelligemment. Pour apprendre, tester, comprendre et construire ses premiers agents IA, c’est déjà une excellente porte d’entrée. Et dans la pratique, un petit modèle rapide, stable et bien intégré sera souvent bien plus utile qu’un énorme modèle lent que vous finirez par abandonner !
Cet article vous a-t-il été utile ?
Votre retour aide à mieux choisir les prochains sujets.
0 retour